Good Morning,
I've been thinking about how applications evolve, and what we might do if we're unhappy with the results. Three apparently unrelated ideas have been percolating in my head. In this newsletter I'll introduce each one and connect them together, in hopes that understanding these connections will help us understand our apps.
These thoughts are very definitely my opinion, justified only by past experience. YMMV, but it'll give you something to think about. :-) Expect lots of pictures. Imagine me waving my arms and drawing on the whiteboard.
The first idea is Martin Fowler's Design Stamina Hypothesis.
#1: Design Stamina Hypothesis
Fowler illustrates this idea with the following graph.
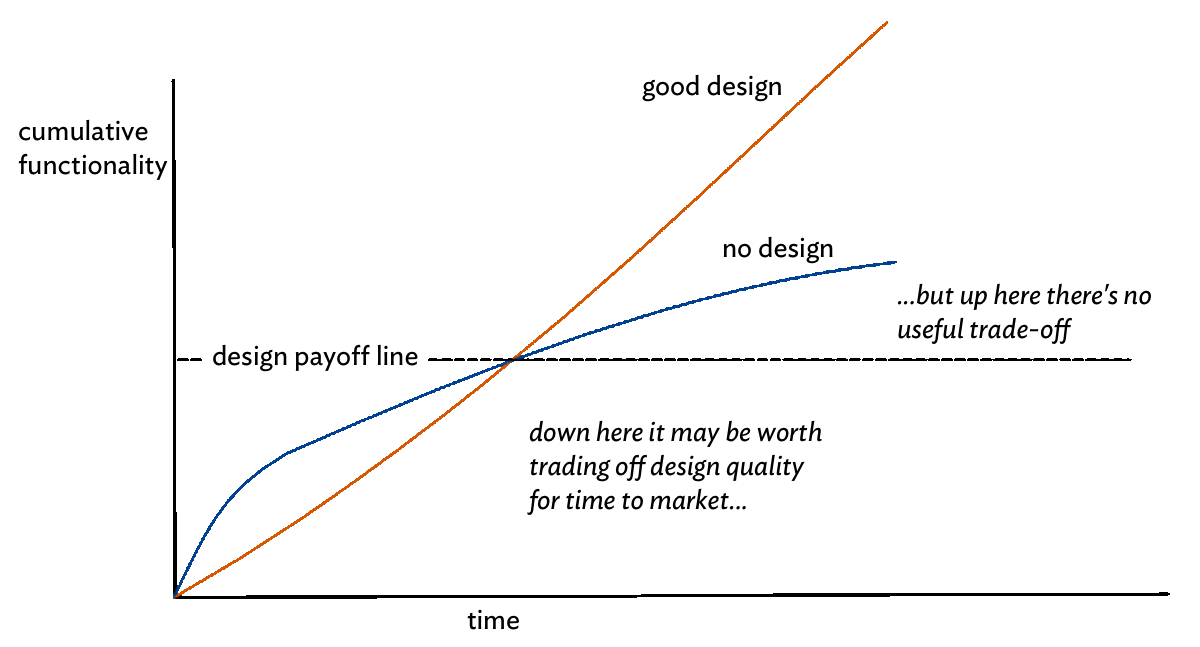
Figure 1
The vertical axis above represents cumulative functionality. The higher the line, the more that got done. The horizontal axis represents time passing. The further to the right, the later in time.
Two different lines are plotted. The orange line illustrates how much functionality you will produce by any point in time by investing in design from day one. The blue line illustrates the outcome if you defer serious design. Notice that the blue line rises fastest early on, but that the orange line eventually overtakes it.
The Design Stamina Hypothesis suggests that early on in a project you'll get more done if you don't bother too much with design, but a point will come when you'll be better off if you invest some energy into it.
The next idea is about the difference between procedural and object-oriented code.
#2: Procedural vs Object-Oriented Code
The section compares procedural and OO code in terms of changeability and understandability. The following graph explores the trade-offs between the two.
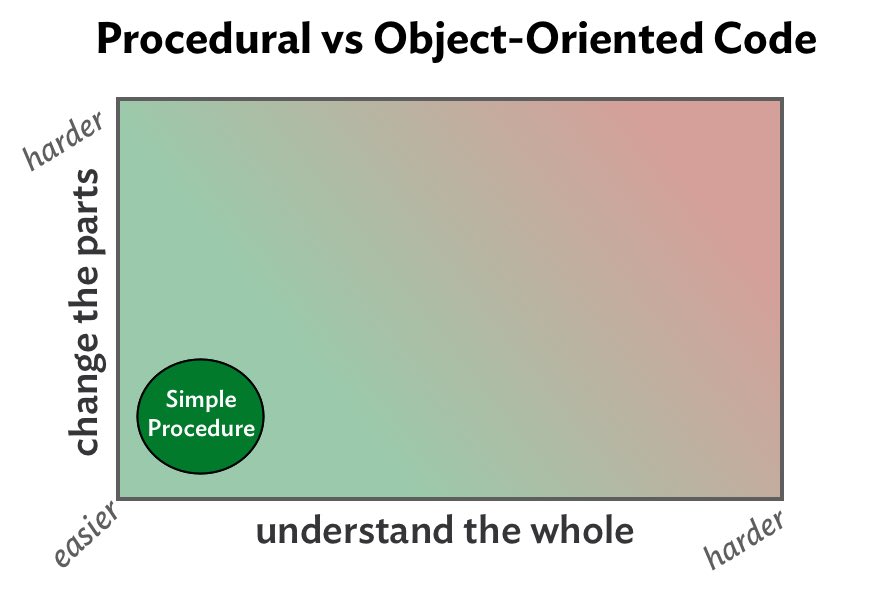
Figure 2
Changeability is plotted on the vertical axis above. Code that is easier to change goes at the bottom. Code that is harder to change, at the top.
Understandability is represented by the horizontal axis. Easier to understand code goes to the left, harder to understand code, to the right.
A simple procedure is merely a list of steps. Simple procedures are easy to understand and easy to change, and so fall into the lower left part of the graph above. This is the most cost-efficient place to be.
For some problems, simple, non-conditional, non-duplicated procedural code is the best solution. What could be cheaper? Write the code and run.
Over time, however, the situation might change. A new feature request might force the addition of conditional logic, or the duplication of parts of the solution in other places, leading to Figure 3 below.
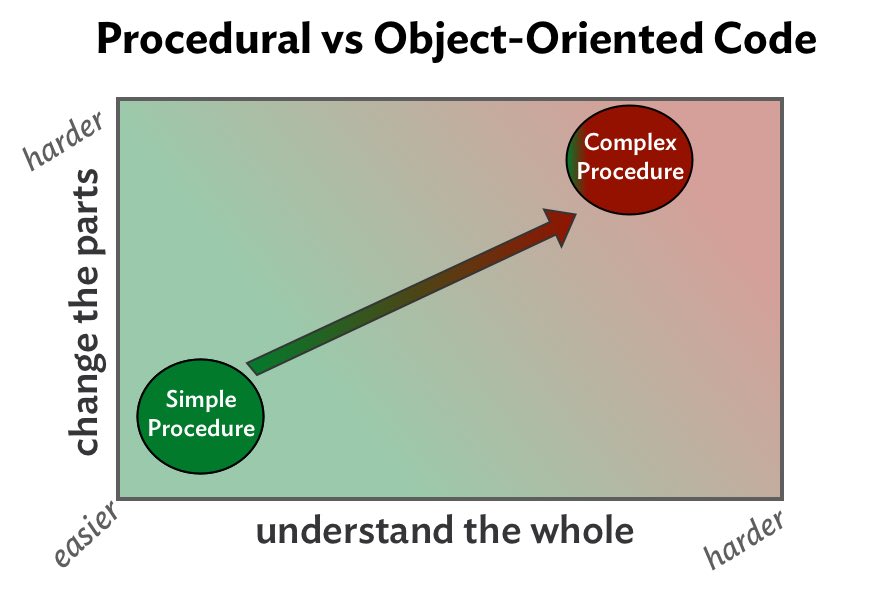
Figure 3
Above, the cost-effective procedure has morphed into a complicated, condition-laden, duplicative morass of code that's hard to understand or change.
Simple procedures are cheap. Complicated procedures are expensive. The only compliment you can pay a complicated procedure (and this is really scraping the bottom of the barrel) is to say that at least all of the #$%@! code is in one place. However, proximity alone is not enough to justify this complexity. There are more cost-effective ways to arrange code.
The next graph adds object-oriented code to the mix. Notice that the OO solution is a little more costly than a simple procedure but far less costly than a complex one.
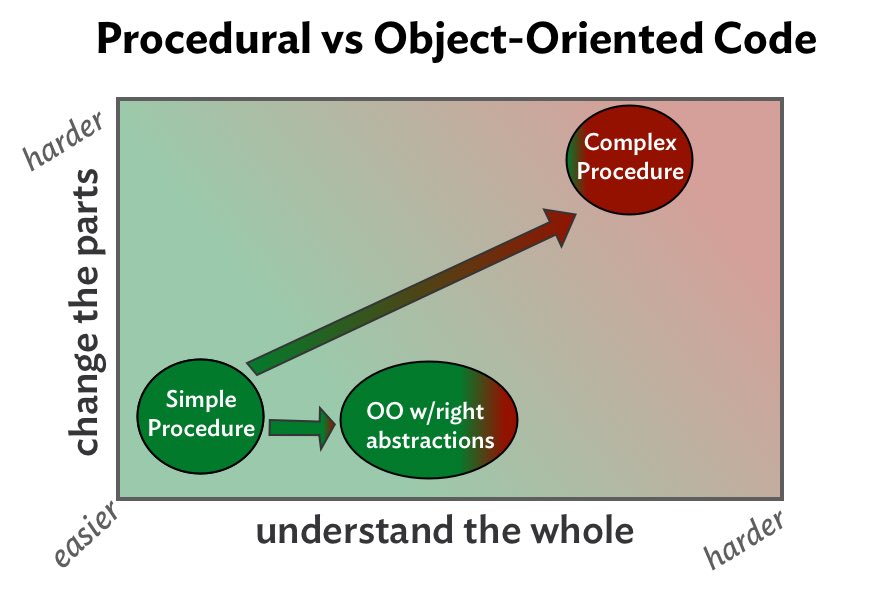
Figure 4
In object-oriented solutions, small, interchangeable objects collaborate by sending messages. Messages afford seams which allow you to replace existing objects with new ones that play the same role. Message sending makes it easy to change behavior by swapping in new parts.
Another consequence of message sending is that it obscures the details of what happens as a result. From the senders' point of view, a message represents only an intention. The receiver of the message supplies the implementation, which is hidden from the sender. Messages bestow effortless local substitutability at the cost of ignorance of distant implementation.
Relative to complex procedures, OO is easier to understand and change. Relative to simple procedures, OO can be as easy to change, but might well be harder to understand as a whole.
So, OO isn't a slam-dunk, hands-down winner. It depends on the complexity of your problem and the longevity of your application.
Speaking of longevity, let's move on to the final idea, churn.
#3: Churn and Complexity
Michael Feathers' Getting Empirical about Refactoring article introduces the idea of churn. Churn is a measure of how often a file changes. Files that change more have higher churn.
Churn is interesting in isolation, but it's even more useful to consider churn alongside complexity. Feathers' article includes the following chart, to which I've added the curved green line.
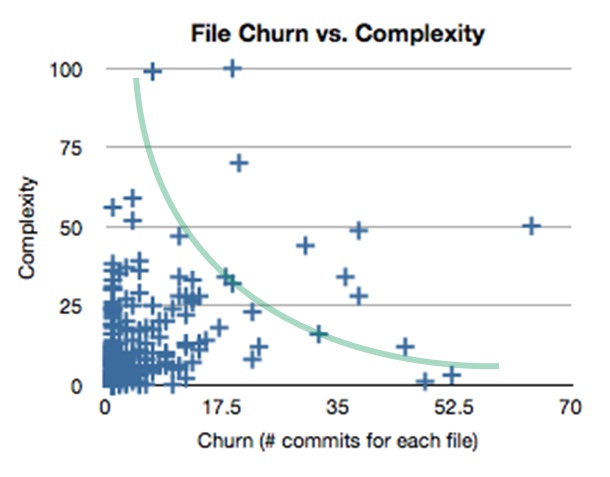
Figure 6
Above, churn is on the horizontal axis. Code complexity is on the vertical.
Complicated code that rarely changes appears in the upper left quadrant of this graph. We abhor complication, but if the code never changes, it's not costing us money. Pretend the code is a cabinet overstuffed with teetering Tupperware: just quietly press the door closed and sneak away. Ignore code in this quadrant until it starts to churn.
Simple code that changes a lot falls into the lower right quadrant. If code is simple enough (think configuration file) it will be cheap to change. Change this code as often as necessary, as long as it remains simple.
The lower left quadrant contains things that aren't very complicated and that don't change much, so this code is already cost-effective and can also be ignored.
The green line curves from upper left, through lower left, and into lower right. This illustrates the curve around which we'd like the code in our apps to cluster. Notice that this line does not enter the top right quadrant.
The top right quadrant reflects complicated code that changes often. By definition, code like this will be hard to understand and difficult to change. We'd prefer this quadrant to be empty, so code that slithers into it should be refactored right back out of it.
Now that we have these ideas in common, I can lean on them to explain a way in which applications go wrong.
Code Evolves Towards a Predictable Kind Of Mess
There's a kind of code mess I see repeatedly, where'er I travel. Courtesy of Code Climate, here are a few graphs that expose its symptoms in several projects (as of Sept 7, 2017).
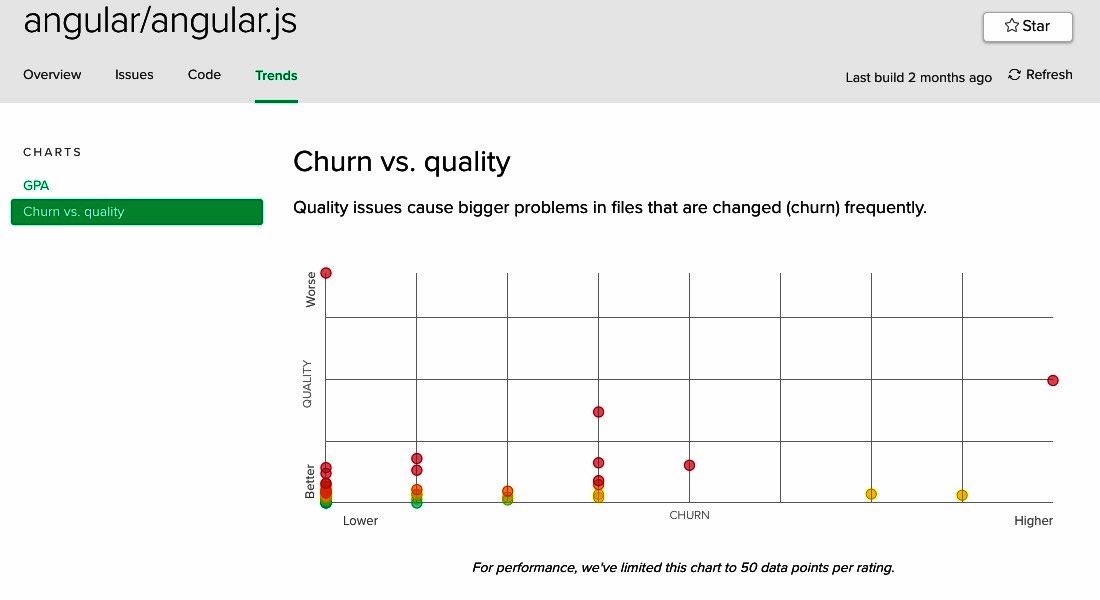
Figure 7
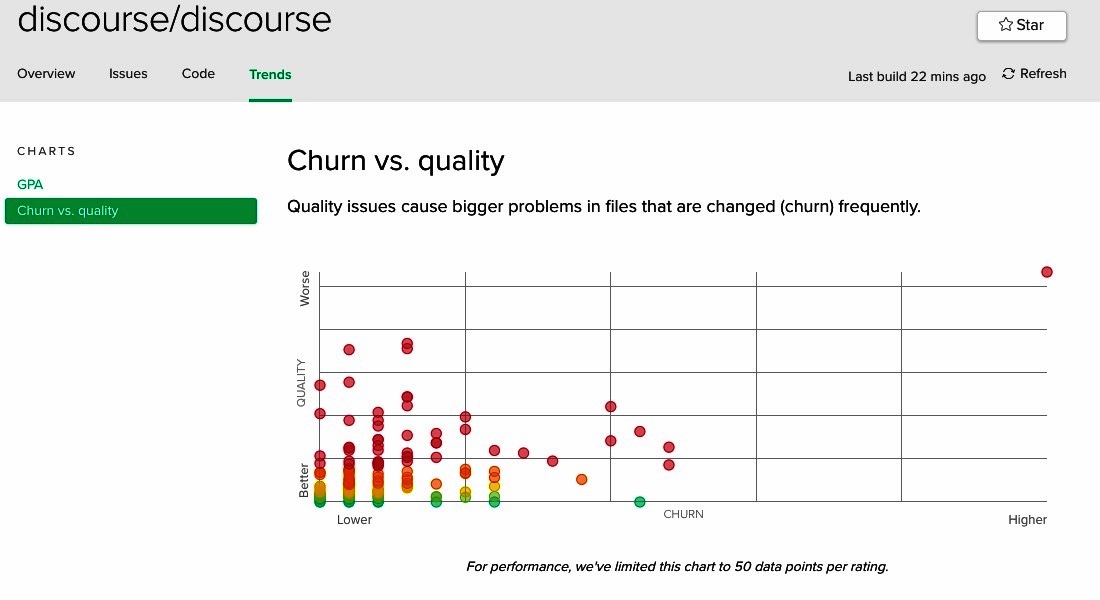
Figure 8
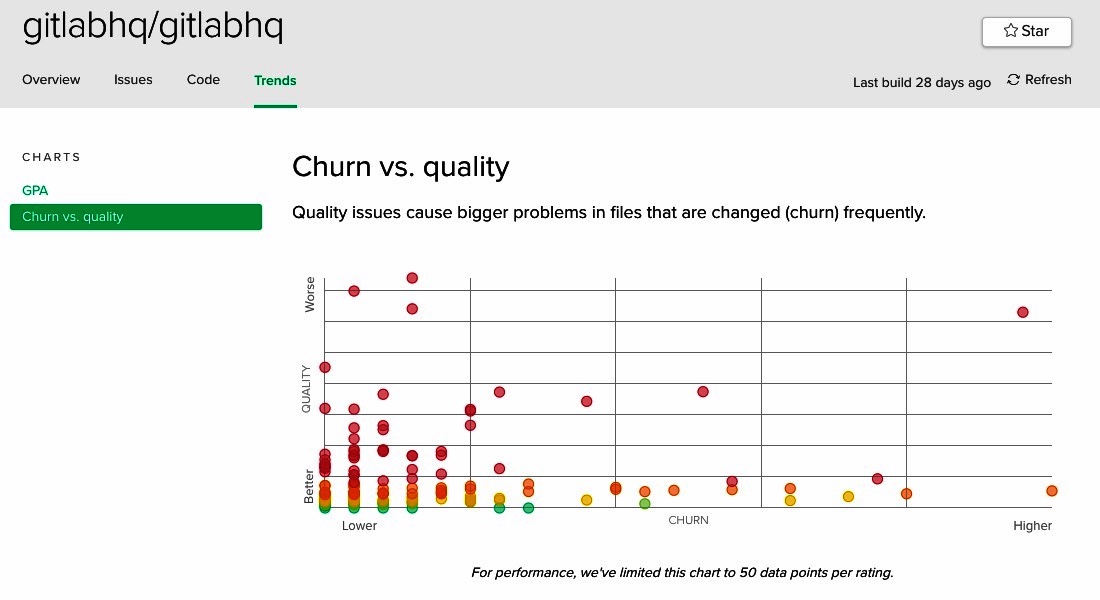
Figure 9
The Churn vs. quality charts above are Code Climate's variant of Michael Feathers' File Churn vs. Complexity idea. Notice that on each of these charts the points cluster around a curve similar to the green line in Figure 6. This is good. It is commendable that in these applications most of the complex code changes little, and most changes are to simple code.
However, each of these graphs also contains an unwanted outlier that resides in the top right quadrant. I'm not familiar with the source code for these apps, but sight unseen I feel confident making a few predictions about the outlying classes. I suspect that they:
- are larger than most other classes,
- are laden with conditionals, and
- represent core concepts in the domain
You can verify this, if you care to, by clicking on each graph above to open the corresponding page in Code Climate. Once there, click on the dot of the outlier to link to the underlying code. As I've already confessed, I don't really know these apps so what do I know...but based on name, size, complexity and churn, I can't help but believe I'm correct. If I'm wrong, or if the code has changed by the time you look, just ignore the example and continue to trust the principle. :-)
Many applications express this pattern. Much of their code is fairly understandable and reasonably easy to change. However, they also contain one or two large, complex, and constantly churning classes that represent extremely important ideas in their domain.
Everyone hates working on these outlier classes. To touch them is to break them. The tests don't provide safety. And no attempted cure helps. Despite best efforts, these classes continue to grow in size and complexity. They're headed from bad to worse.
How does this happen?
We can use a combination of the first three ideas to explain the problem, and understanding the problem offers hope of preempting it.
I posit the following:
If you do design too early, you'll waste your efforts.
(Figure 1 - The orange line early in time)If you never do design, your code will become a painful mess.
(Figure 1 - The blue line late in time)A time will come when investing in design will save you money.
(Figure 1 - Where the lines cross)Simple procedures require little design and are cheap to maintain.
(Figure 2, Figure 1: The blue line early)Procedures become more complex over time, and more expensive to maintain.
(Figure 3, Figure 1: The blue line late in time)Object-oriented code is more cost-effective than complex procedural code.
(Figure 4)The procedures that are most important to your domain change more than those that are incidental to your domain.
The procedures that are important to your domain increase in complexity faster than other code.
It's difficult to be aware of the exact moment when your application crosses the design payoff line.
(Figure 1)You become aware that you have passed the design payoff line because velocity slows and suffering increases. (Figure 1 - blue line beyond the design payoff line)
The most important code will be the most out-of-control by the time you realize you've passed the design payoff line.
Moderately complex procedures are easy to convert to OO.
Extremely complex procedures are more difficult to convert to OO.
Your attempts to convert moderately complicated procedures to OO generally succeed.
Your attempts to convert extremely complicated procedures to OO often fail.
This is how we end up with applications where many small, efficient classes coexist alongside one costly, massive, condition-filled behemoth. A series of small, innocent changes turned the application's most important code into a class so complex that no one could fix it. The problem becomes visible at item 15 above, but its roots lie in item 8, where tiny bits of complexity got added, repeatedly, until the logic passed the point of no return.
Sticking with procedures too long is just as bad as doing design too soon. If important classes in your domain change often, get bigger every time they change, and are accumulating conditionals, stop adding to them right now. Use every new request as an opportunity to do a bit of design. Implement the change using small, well-designed classes that collaborate with the existing object.
A 5,000 line class exerts a gravitational pull that makes it hard to imagine creating a set of 10 line helper classes to meet a new requirement. Make new classes anyway. The way to get the outliers back on the green line where they belong is to resist putting more code in objects that are already too large. Make small objects, and over time, the big ones will disappear.
Best,
Sandi
News: 99 Bottles of OOP in JS, PHP, and Ruby!
The 2nd Edition of 99 Bottles of OOP has been released!
The 2nd Edition contains 3 new chapters and is about 50% longer than the 1st. Also, because 99 Bottles of OOP is about object-oriented design in general rather than any specific language, this time around we created separate books that are technically identical, but use different programming languages for the examples.
99 Bottles of OOP is currently available in Ruby, JavaScript, and PHP versions, and beer and milk beverages. It's delivered in epub, kepub, mobi and pdf formats. This results in six different books and (3x2x4) 24 possible downloads; all unique, yet still the same. One purchase gives you rights to download any or all.
